By Tim van der Meijden, Lombard de Leeuw and Joost Schoonhoven
Introduction:
BinPi is a start-up company established by three young professionals. BinPi works in collaboration with the minor Smart Manufacturing and Robotics at The Hague University and focuses on finding cost-efficient Bin Picking solutions.
The assignment:
BINPI’s focus is to enhance the method of finding specified parts in a bin, also known as bin picking. BINPI’s current goal is to create a solution with the use of a 2D camera and preloaded 3D models. The challenge in this assignment is to find depth and 3D orientation with a software solution
Our testing object is a PVC corner piece (see picture).

The solution
To find an alternative approach, we view the current bin picking problem as a PnP problem (perspective n point problem) (Xirouhakis et al.). With this view, we approach our problem as a pose estimation with solutions similar to human pose estimation (Newell et al.). By predetermining keypoints on our known 3D model, as well as on training images, we train a neural network to estimate the keypoint locations on a given image. With enough keypoints, we scale down the number of variants of poses an object can have. With the found pose and corresponding keypoint coordinates, we are able to determine the exact pick up location on the object relative to the camera. By transforming the vector coordinates of the image location to real world location, we can create a robot command to pick up the object.
Pre-processing:
The image pre-processing is an important step to evaluate where what is. Through defining which components the machine has to find, the machine can assess what filter it needs to get the right objects. After the processing the image of the part without filter is send to the machine-learning black–box.

Machine learning:
BINPI uses a Geometric machine learning model to determine the pixel locations of predetermined keypoints on an image. These keypoints are predetermined on a 3D object model. By finding enough keypoints on an image, the number of possible variances an object can have can be scaled down significantly and the pose and position of the object in the image can be associated with a possible pose and position of the object model. By allocating possible pickup points to the keypoints in the model a pickup location can be determined and a pickup sequence can start.

Virtual environment:
To train a machine learning algorithm, a dataset of images and pre-determined keypoints of objects are needed. This can be generated quickly in a virtual environment. In the program ‘Blender’, the scene of the camera in the real world is simulated with the same objects and the same lighting.
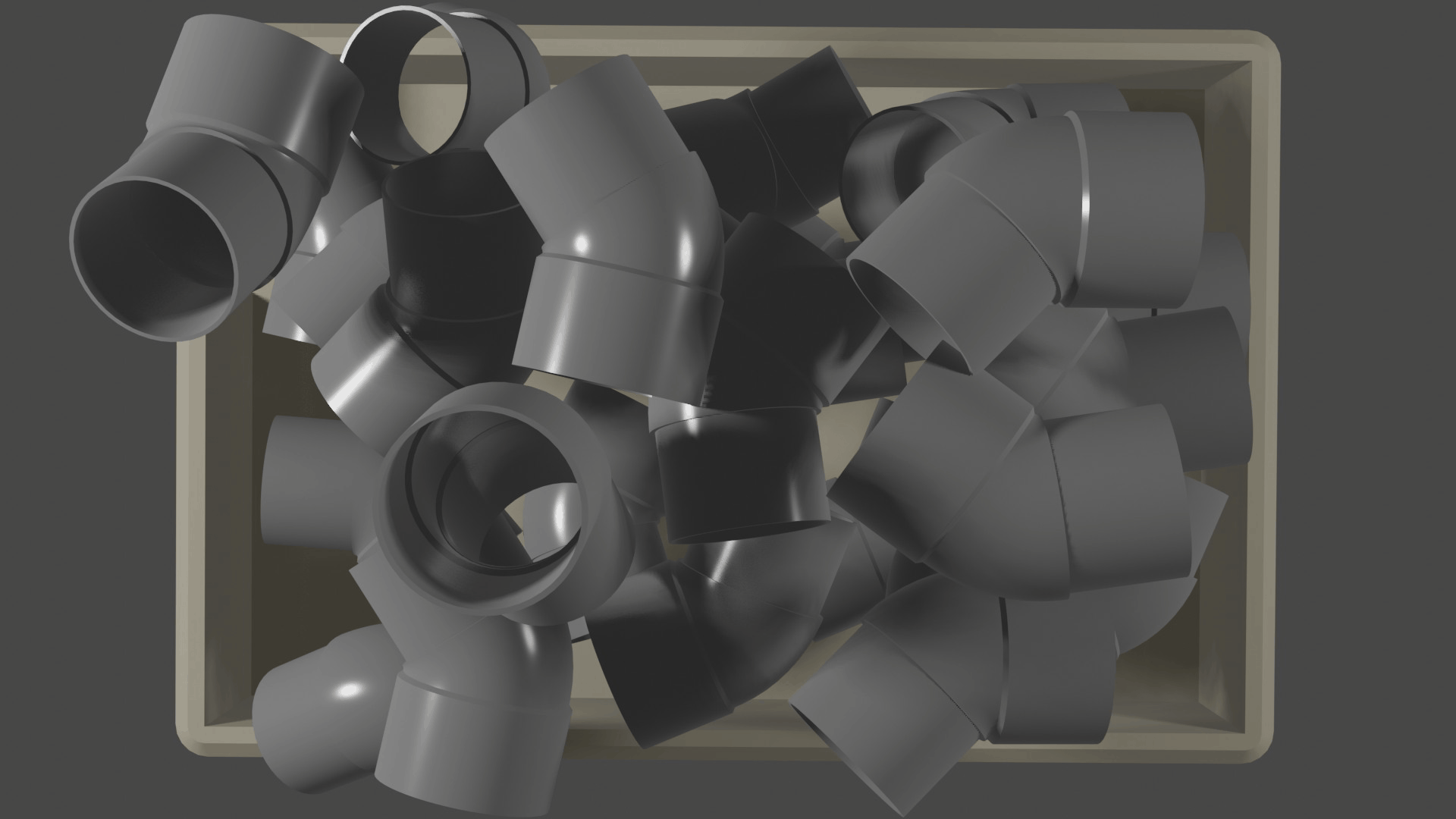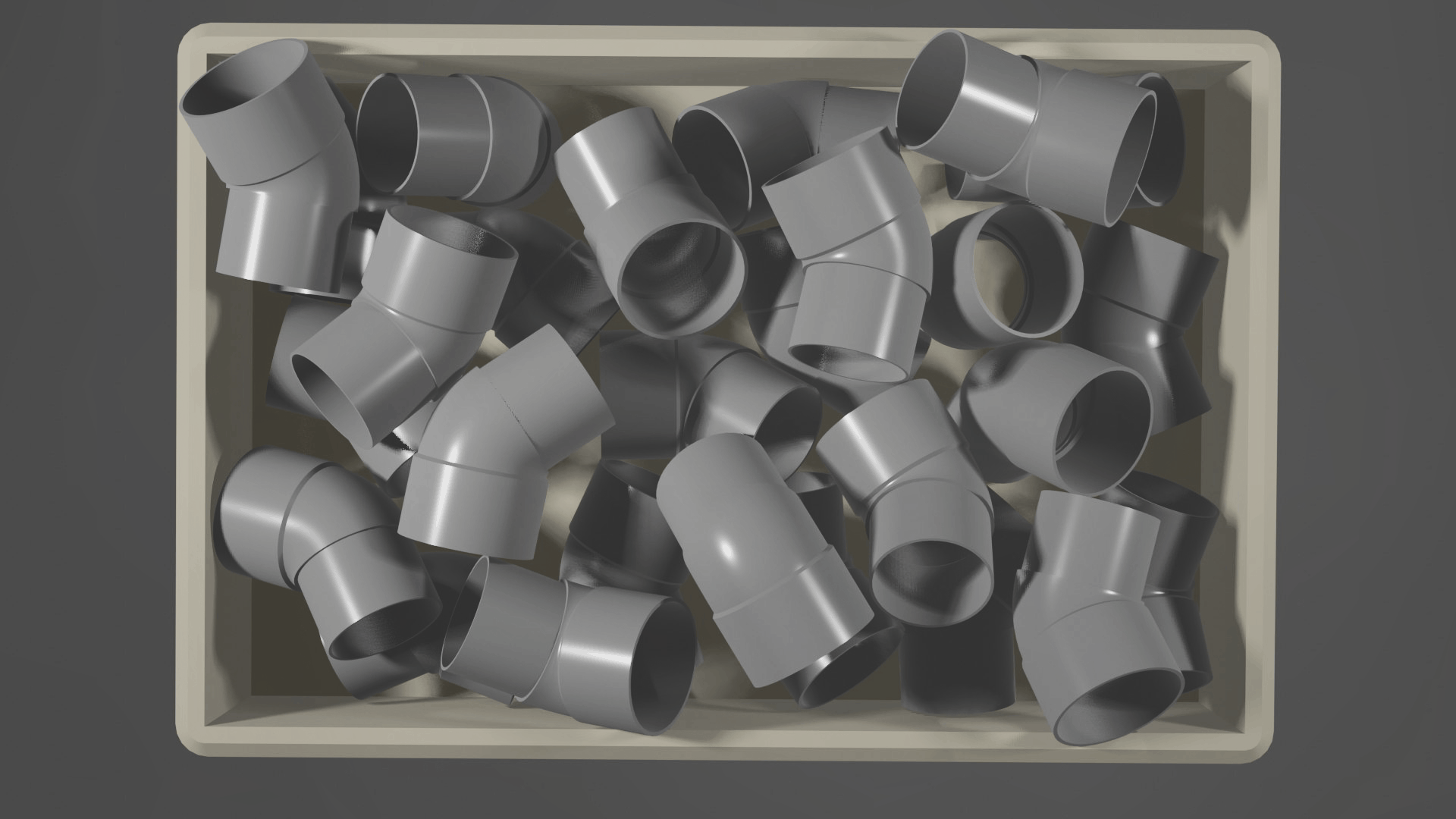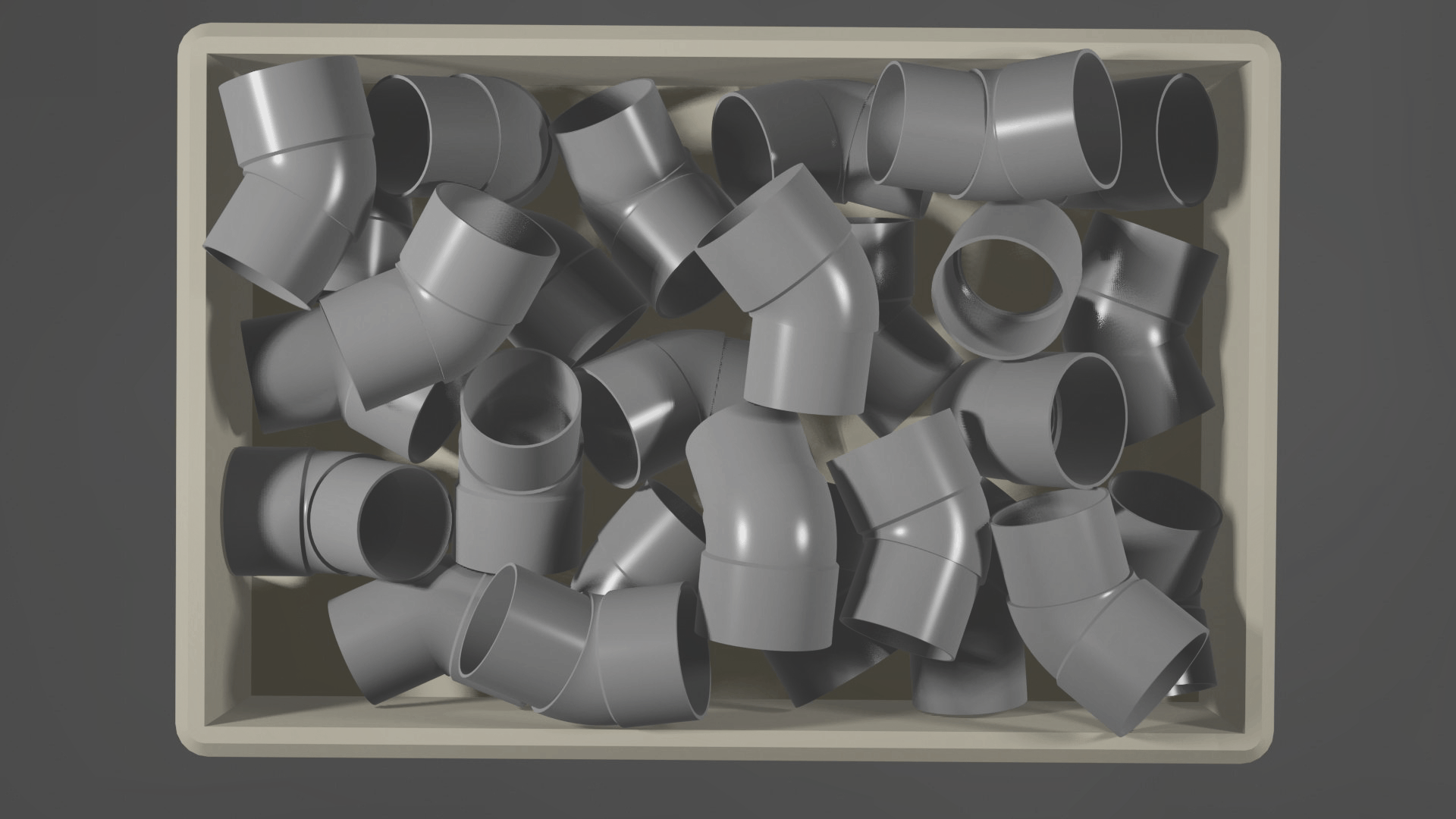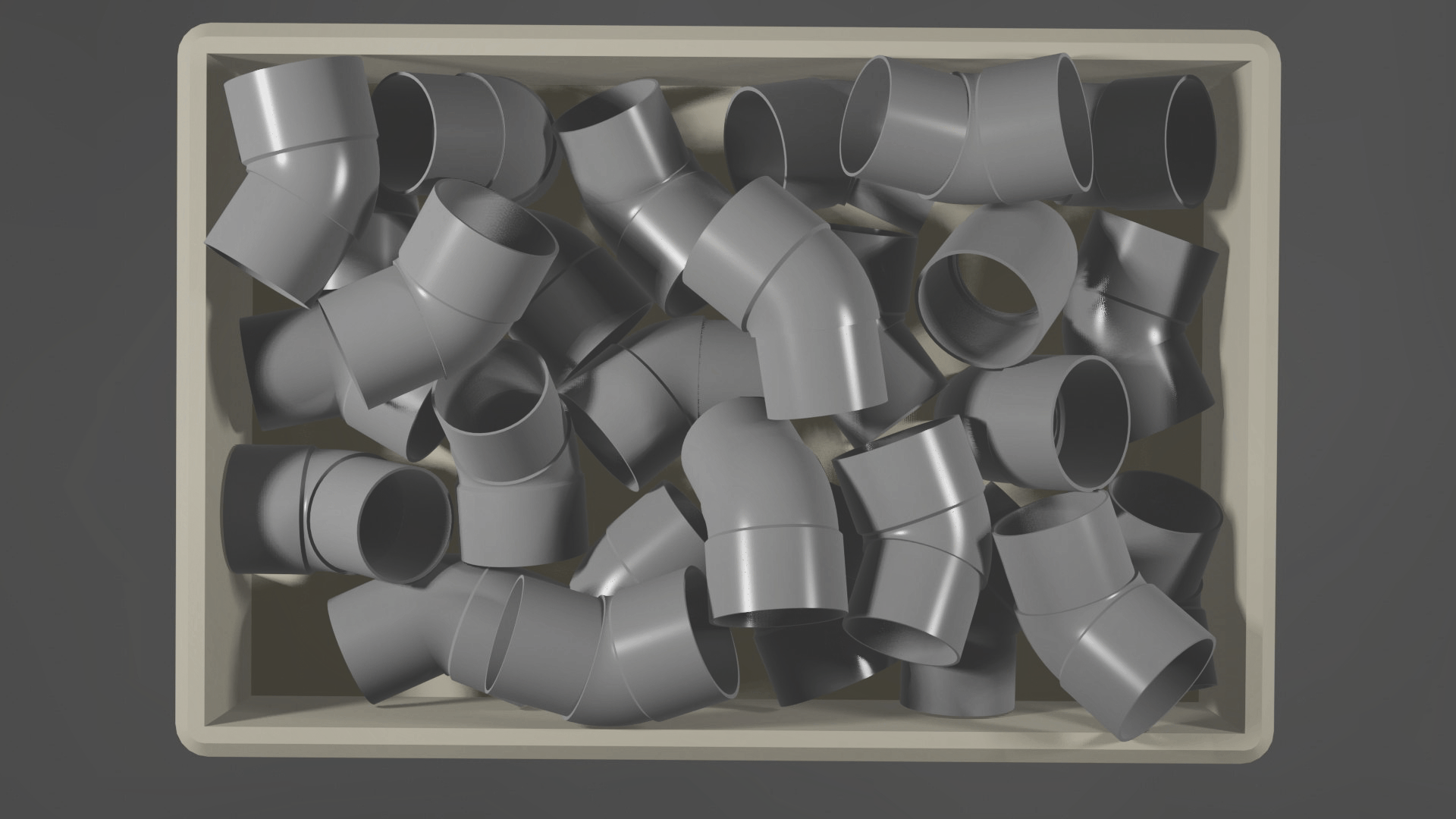
Calibration:
To determine fixed points in the real-world, calibration plates are placed. These plates are fixed with a certain coordinate. For the robot these plates are always on the same place. For the camera it can differ. The reason being that the structure for the camera can be a bit unstable.
Blackbox:
For a fixed environment for our vision and machine-learning model. BINPI made a frame around the robot so the only the robot needs to see is visible. The Blackbox is surrounded by black paper to keep the environmental lighting out and keep its own lighting on the inside. This makes for an easier and a more consistent work environment for the vision part and machine-learning training.
EOAT:
For the picking of the parts we made a tool-changer. The base is mounted on the robot and the tool is fixed with a locking mechanism and magnets. The base has two inputs for a signal wire and one output for the pneumatics. The tool we currently use is a vacuum gripper (see image …).

This tool also has a collision detector and a vacuum suction cup. The collision detector is in case the tool is just a bit off it will return to a save position after a collision to avoid damage to the tool, the robot or the working environment.
Literature:
[1] Xirouhakis Y., Delopoulos A., “Least squares estimation of 3D shape and motion of rigid objects from their orthographic projections”, Pattern Analysis and Machine Intelligence IEEE Transactions on, vol. 22, no. 4, pp. 393-399, 2000.
[2] Newell A., Yang K., Deng J. (2016) Stacked Hourglass Networks for Human Pose Estimation. In: Leibe B., Matas J., Sebe N., Welling M. (eds) Computer Vision – ECCV 2016. ECCV 2016. Lecture Notes in Computer Science, vol 9912. Springer, Cham
Students:
Lombard de Leeuw: https://www.linkedin.com/in/lombard-de-leeuw-3b53a9a7/
Tim van der Meijden: https://www.linkedin.com/in/timvandermeijden/
Joost Schoonhoven: https://www.linkedin.com/in/joost-schoonhoven-066894ab/